ในบทความนี้ คุณจะได้สำรวจวิธีการดึงข้อมูล เช่น ข้อความจากรูปภาพ ซึ่งจะช่วยให้คุณใช้ข้อมูลดังกล่าวได้อย่างมีประสิทธิภาพ เพื่อปรับปรุงประสิทธิภาพของ AI
การใช้ AI ร่วมกับเทคโนโลยีการจดจำอักขระด้วยแสง (OCR) ช่วยให้ธุรกิจสามารถดึงข้อมูลจากภาพได้ จึงทำให้กระบวนการป้อนข้อมูลมีประสิทธิภาพขึ้น ลดความพยายามด้วยตนเอง และลดความเสี่ยงต่อข้อผิดพลาดให้เหลือน้อยที่สุด
แนวทางนี้อำนวยความสะดวกในการแปลงข้อมูลสำคัญจากรูปภาพเป็นรูปแบบข้อความ ช่วยให้ธุรกิจต่างๆ สามารถอัพโหลดข้อมูลเป็น แหล่งความรู้ได้ ส่งผลให้การตอบกลับของ AI มีความแม่นยำมากขึ้น และมั่นใจได้ว่าคำตอบเหล่านั้นจะเป็นข้อมูลล่าสุด
บทความนี้จะสรุปขั้นตอนการแปลงรูปภาพเป็นข้อความโดยใช้เครื่องมือ AI สองเครื่องมือในตลาด ได้แก่ Sider และ ChatGPT-4 สำหรับการพิจารณาของคุณ โปรดอ่านต่อไปเพื่อดูว่าเครื่องมือใดเหมาะกับความต้องการทางธุรกิจและงบประมาณของคุณ
1. ไซเดอร์
สกัดข้อความ ตัวเลข และสมการจากรูปภาพ
สามารถจดจำลายมือภาษาอังกฤษได้เท่านั้น
คุณสมบัติการสกัดข้อมูลนั้นฟรี แต่ต้องมีการอัปเกรดแบบชำระเงินเพื่อใช้คุณสมบัติเพิ่มเติม
ต้องใช้โปรแกรมประมวลผลคำเพื่อแปลงข้อความที่แยกออกมาเป็นไฟล์ PDF (สำหรับผู้ที่ต้องการใช้ข้อความที่แยกออกมาเป็นแหล่งความรู้)
2. เครื่องมือแยกข้อความ ChatGPT-4
สามารถจดจำข้อความในภาพได้อย่างแม่นยำ
ใช้งานได้เฉพาะใน ChatGPT-4 เท่านั้น และต้องมีการอัปเกรดแบบชำระเงินเพื่อใช้ฟีเจอร์นี้
สามารถแปลงข้อความที่แยกออกมาเป็นไฟล์ PDF ได้โดยตรง
วัตถุประสงค์ของวิธีการ
ดาวน์โหลดส่วนขยาย Sider บนคอมพิวเตอร์ของคุณ > สร้างบัญชีและเข้าสู่ระบบ
คลิกไอคอน Sider บนแถบส่วนขยายเพื่อเปิดแถบด้านข้าง > คลิกไอคอน OCR
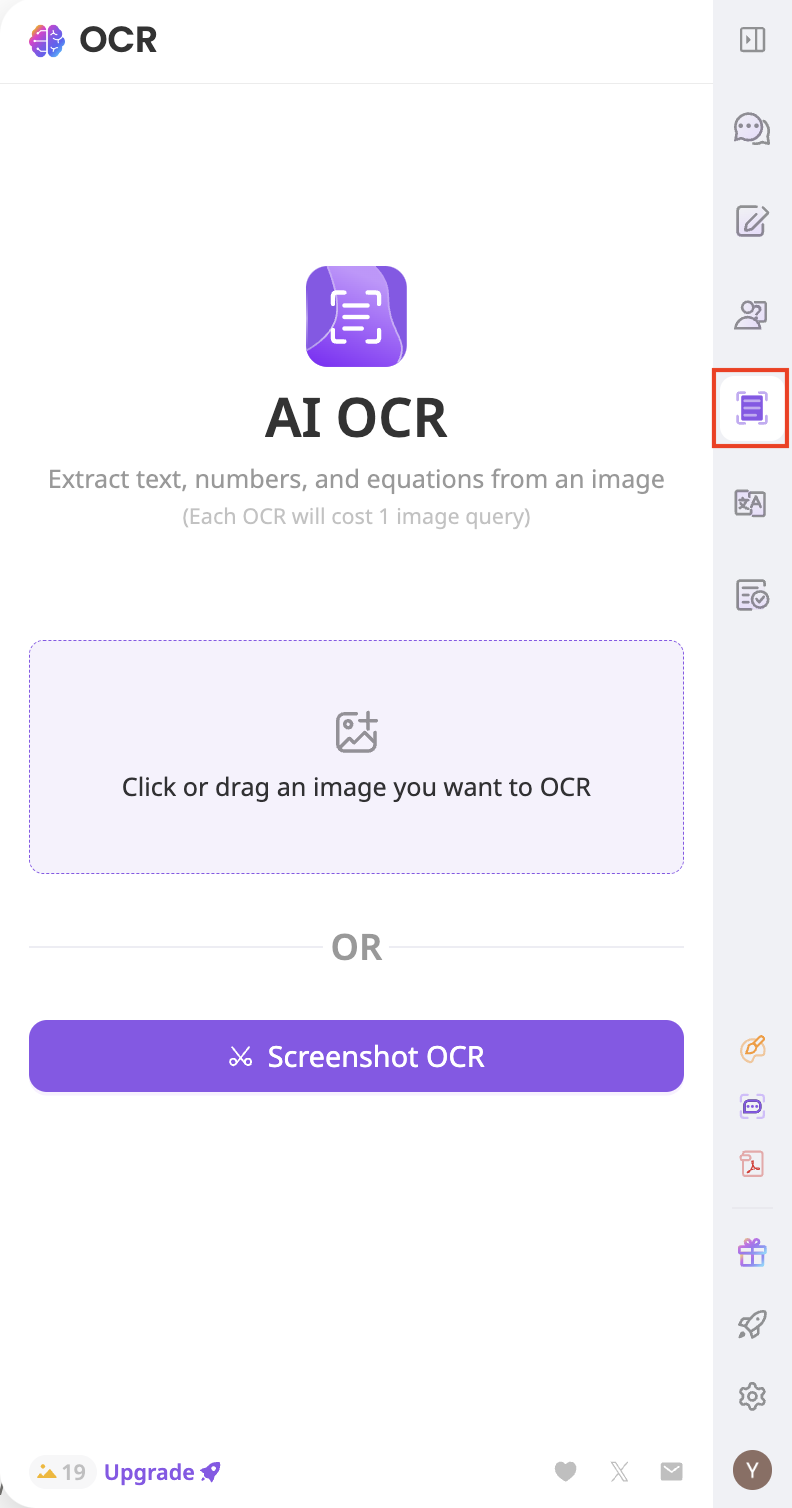
3. อัพโหลดรูปภาพ ตรวจสอบให้แน่ใจว่าขนาดไฟล์น้อยกว่า 10MB และความกว้างหรือความสูงของรูปภาพไม่เกิน 4,096 พิกเซล
อ่าน ที่นี่ เพื่อรับเคล็ดลับเพิ่มเติมเกี่ยวกับวิธีการเพิ่มความแม่นยำของกระบวนการสกัด
หากภาพที่อัพโหลดตรงตามข้อกำหนด กระบวนการแยกไฟล์จะเริ่มต้นโดยอัตโนมัติ และผลลัพธ์จะปรากฏขึ้นเมื่อกระบวนการเสร็จสิ้น
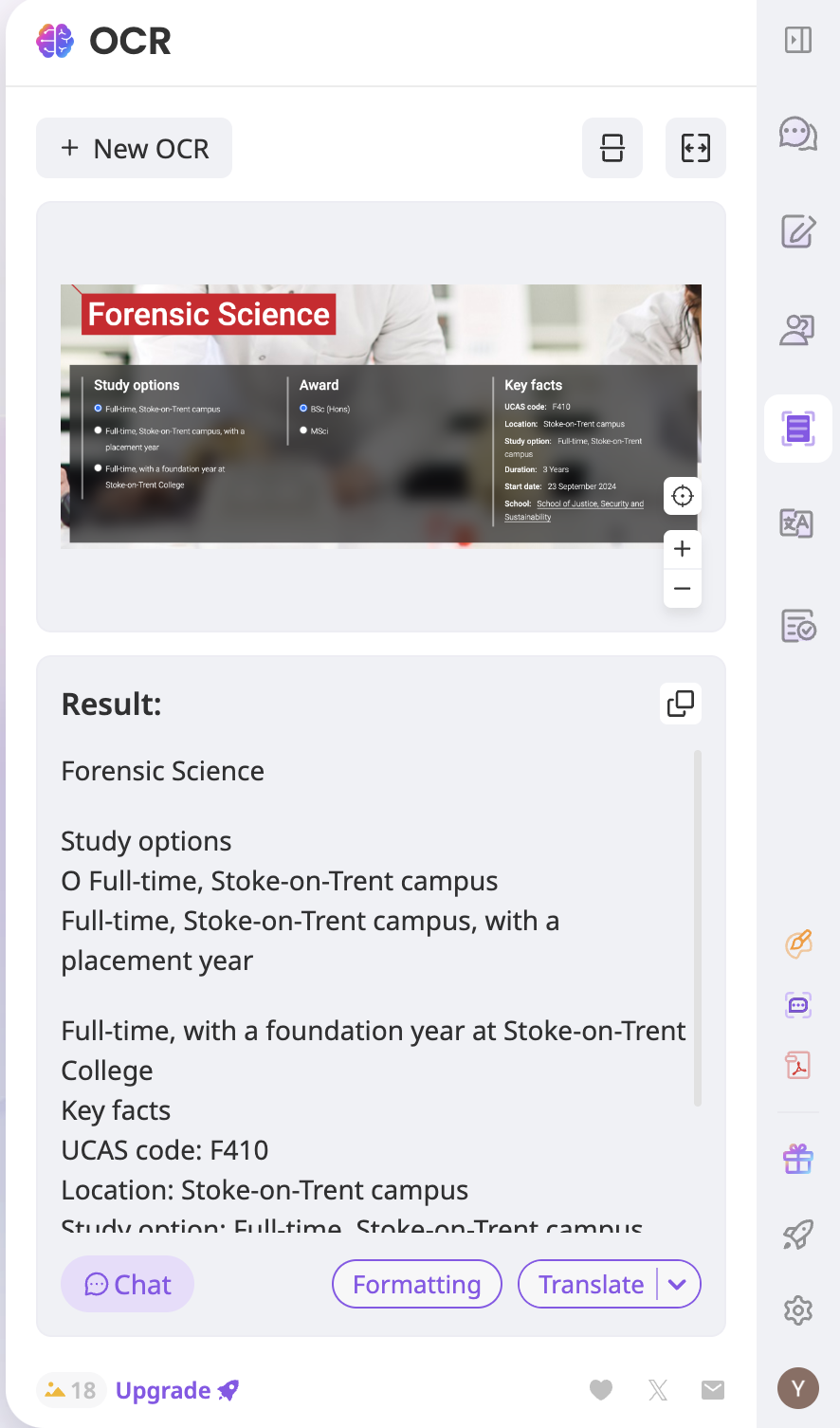
4. คลิก การจัดรูปแบบ เพื่อให้ Sider จัดรูปแบบข้อความให้เป็นเค้าโครงที่สามารถอ่านได้โดยอัตโนมัติ
5. หากต้องการอัปโหลดข้อความที่แยกออกมาเป็นแหล่งความรู้ ให้แปลงข้อความเป็นไฟล์ PDF โดยคลิกไอคอนคัดลอกที่ผลลัพธ์เพื่อคัดลอกข้อความทั้งหมด
6. วางข้อความลงในโปรแกรมประมวลผลคำ (เช่น Microsoft Word หรือ Google Docs) และบันทึกไฟล์เป็น PDF
7. จากนั้นโปรดดู คู่มือ นี้เพื่อเรียนรู้วิธีอัปโหลดไฟล์ PDF เป็นแหล่งความรู้
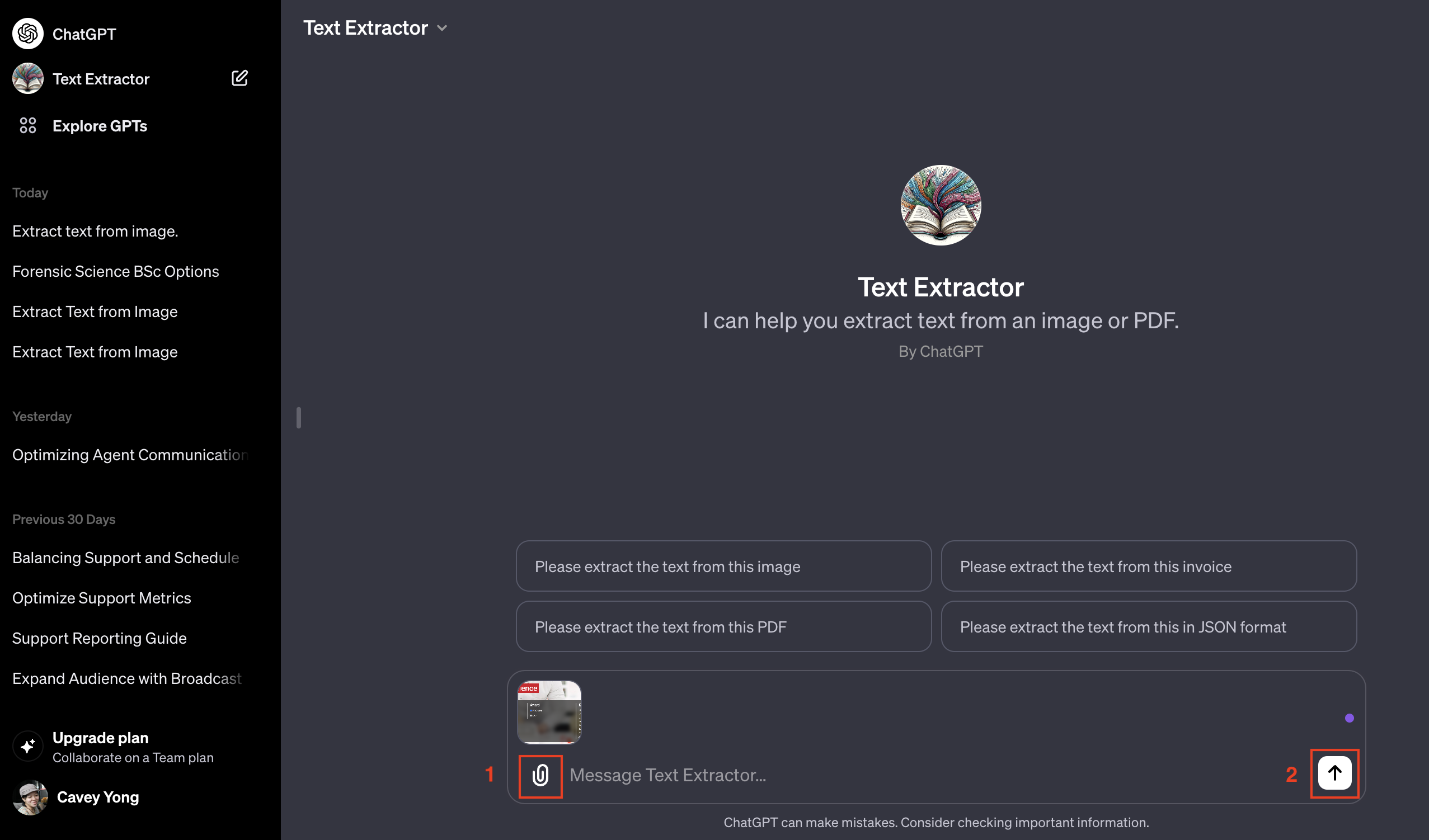
ในText Extractorใน ChatGPT-4 คลิกไอคอน 📎 และอัปโหลดรูปภาพของคุณ ตรวจสอบให้แน่ใจว่าประเภทไฟล์ได้รับการรองรับ เช่น JPEG, PNG, BMP, TIFF หรือ GIF
อ่าน ที่นี่ เพื่อรับเคล็ดลับเพิ่มเติมเกี่ยวกับวิธีการเพิ่มความแม่นยำของกระบวนการสกัด
2. เมื่ออัพโหลดรูปภาพแล้ว ให้คลิกที่ไอคอนลูกศรขึ้นเพื่อเริ่มกระบวนการแยกไฟล์
3. เมื่อกระบวนการสกัดเสร็จสิ้นผลลัพธ์จะแสดง
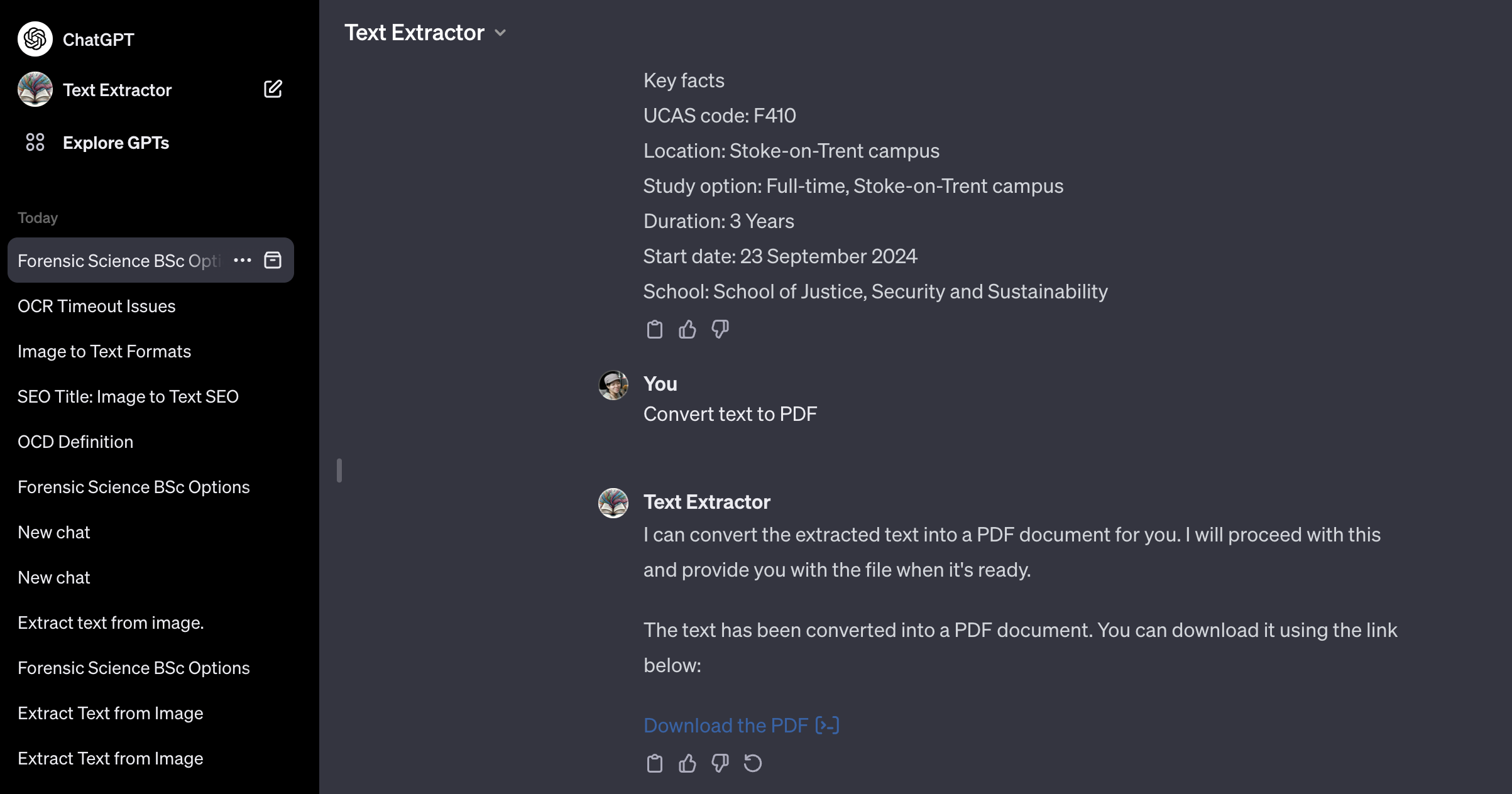
4. หากต้องการอัปโหลดข้อความที่แยกออกมาเป็นแหล่งความรู้ ให้แปลงข้อความดังกล่าวเป็นไฟล์ PDF โดยให้คำแนะนำในการสร้างไฟล์ PDF โดยอิงจากข้อความดังกล่าว ต่อไปนี้เป็นตัวอย่างของคำแนะนำ:
แปลงข้อความเป็น PDF
5. ดาวน์โหลดไฟล์ PDF ที่สร้างขึ้น
6. จากนั้นโปรดดู คู่มือ นี้เพื่อเรียนรู้วิธีอัปโหลดไฟล์ PDF เป็นแหล่งความรู้
ประสิทธิภาพในการแยกข้อความขึ้นอยู่กับความสามารถของเครื่องมือที่ใช้ เพื่อเพิ่มความแม่นยำในการดึงข้อความจากรูปภาพ คุณอาจพิจารณาข้อกำหนดหลักบางประการดังต่อไปนี้:
คุณภาพของภาพ: ใช้รูปภาพที่มีความละเอียดสูงและคมชัด หลีกเลี่ยงภาพที่มีความละเอียดต่ำหรือเป็นพิกเซล
การอ่านข้อความได้ชัดเจน: ใช้รูปภาพที่มีข้อความที่ชัดเจนและอ่านออกได้
การรบกวนบนพื้นหลังให้น้อยที่สุด: ใช้รูปภาพที่มีข้อความทับบนพื้นหลังที่เรียบง่าย หลีกเลี่ยงภาพที่มีข้อความกลมกลืนกับพื้นหลังหรือมีลายน้ำ
การวางแนวข้อความ: ใช้รูปภาพที่มีข้อความที่จัดเรียงในแนวนอน ข้อความที่หมุนเป็นมุมอาจไม่สร้างผลลัพธ์ที่ดีที่สุด




บทความที่เกี่ยวข้อง 👩💻

