在本文中,您將探索提取資訊(例如從圖像中提取文字)的方法,從而使您能夠有效地使用這些資訊來增強 AI 的性能。
使用具有光學字元辨識 (OCR) 技術的人工智慧,企業能夠從影像中提取訊息,從而簡化資料輸入流程、減少手動工作量並最大限度地降低錯誤風險。
這種方法有助於將圖像中的關鍵資訊轉換為文字格式,使企業能夠將資訊上傳為 知識源。 因此,這有助於提高人工智慧回應的準確性,確保它們是最新的。
本文概述了使用市場上的兩種 AI 工具 Sider 和 ChatGPT-4 將圖像轉換為文字的步驟。 為了您的考慮,請繼續閱讀以了解哪種工具適合您的業務需求和預算。
1. 西德
從圖像中提取文字、數字和方程式。
它只能辨識英文手寫內容。
提取功能是免費的,需要付費升級才能使用附加功能。
需要文字處理器將提取的文本轉換為 PDF 文件(對於那些想要使用提取的文本作為知識來源的人)。
2. ChatGPT-4 文字擷取器
可以準確辨識圖像中的文字。
僅在 ChatGPT-4 中可用,且需要付費升級才能使用此功能。
可以直接將擷取的文字轉換為PDF檔案。
方法目標
使用 Sider將圖像轉換為文字。
在你的電腦上下載 Sider 擴充 > 建立一個帳戶並登入。
點選擴充欄上的 Sider 圖示啟動側邊欄 > 點選 OCR 圖示。
3. 上傳圖片。 確保檔案大小小於 10MB,且影像的寬度或高度不超過 4096 像素。
閱讀 這裡 以獲取有關如何提高萃取過程準確性的更多提示。
如果上傳的圖像符合要求,提取過程將自動開始,提取完成後將顯示結果。
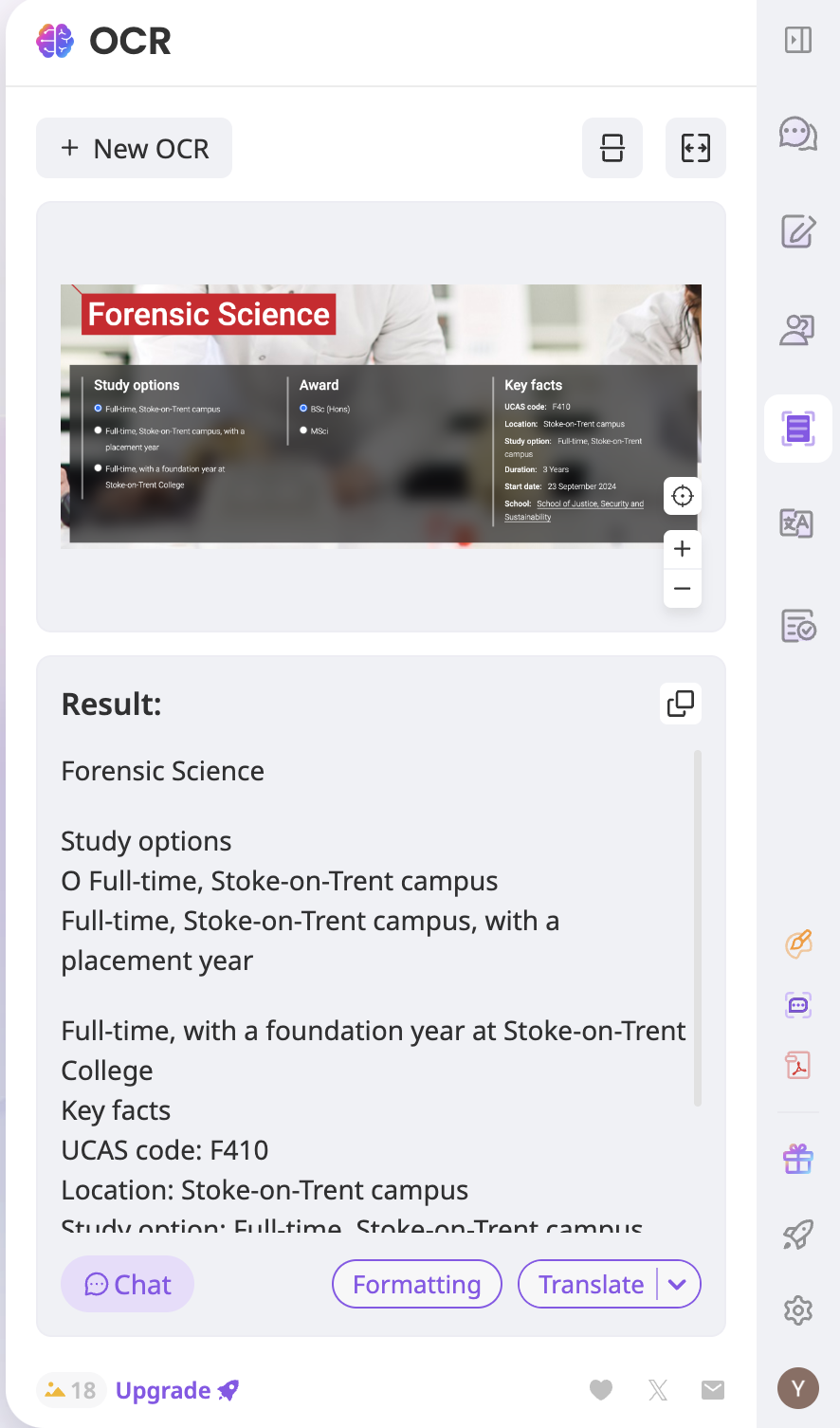
4. 點選 格式化 ,讓 Sider 自動將文字格式化為可讀取的佈局。
5. 若要將提取的文本上傳為知識來源,請按一下結果中的複製圖示複製整個文本,將文字轉換為 PDF 檔案。
6. 將文字貼到文字處理器(例如 Microsoft Word 或 Google Docs)並將文件儲存為 PDF。
7. 然後,參考 本指南 了解如何將 PDF 檔案上傳為知識來源。
在 ChatGPT-4 中的文字擷取器上,點擊 📎 圖示並上傳您的圖像。 確保文件類型受支持,例如 JPEG、PNG、BMP、TIFF 或 GIF。
閱讀 這裡 以獲取有關如何提高萃取過程準確性的更多提示。
2. 圖像上傳後,點擊向上箭頭圖示開始提取過程。
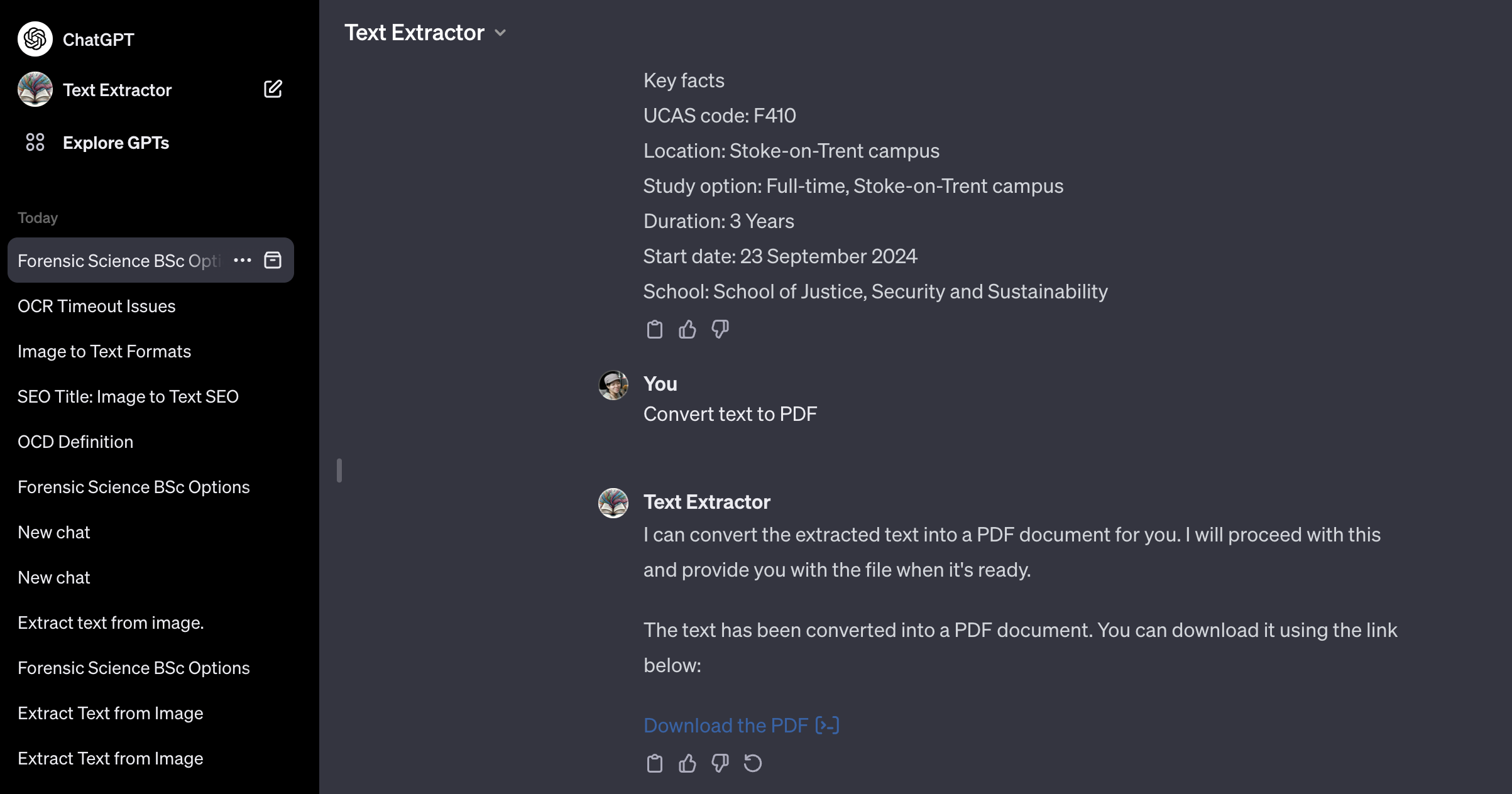
3. 提取過程完成後,將顯示結果。
4. 若要將擷取的文字作為知識來源上傳,請透過提供基於文字產生 PDF 檔案的指令將文字轉換為 PDF 檔案。 以下是該指令的範例:
將文字轉換為 PDF
5. 下載產生的 PDF 檔案。
6. 然後,參考 本指南 了解如何將 PDF 檔案上傳為知識來源。
文字擷取的有效性取決於所用工具的功能。 為了提高從圖像中提取文字的準確性,您可以考慮以下列出的一些關鍵要求:
影像品質: 使用高解析度和清晰的影像。 避免使用低解析度或像素化的影像。
文字清晰度: 使用有清晰易讀的文字的圖像。
對背景的干擾最小: 在簡單的背景上使用帶有文字的圖像。 避免使用與背景融合的文字或帶有浮水印的圖像。
文字方向: 使用水平對齊的文字影像。 以一定角度旋轉的文字可能不會產生最佳效果。





